Why Search?
Imagine to locate a file in your machine with no search provided in explorer or by the operating system. Sure it's a scary thing to attempt unless you're retired or bored of life :), search saves a ton of time and efforts in these hard-times.
Enterprise Search:
As we know searching within a single machine for a document itself is tiresome and an enterprise is amassed with many such systems and finding a file in such distributed environments gets really tough. Enterprise search does the lookup for you across all these systems and provides the most relevant results.

source: programming-free.com
Amazon sold a little over 3 billion products in October 2017, that's a minimum of billion queries unless they found stuff on the home page which is not customized for the consumer suppose if this shopping giant had no search and probably organised stuff by categories and asked you to find your product then your approximate worst case time complexity in finding a product would be somewhere around O(410,058,418) and this only for top 10. Here are the top 10 categories and their distribution:
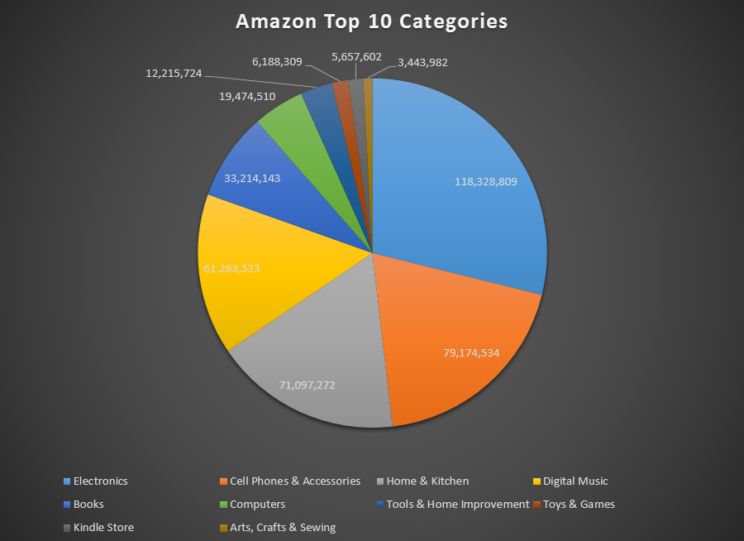
source: scrapehero
So enterprises when they get huge demands the need of a search tool. My bad i forgot the classic Google example if there's no google help imagine finding a document on world wide web.
Search in Analytics:
Having search on website really helps study the customers, business and to plan for the future. when a search is made any analytics on the query will help improve the results over time, know customers requirements, provide suggestions for different products and improve business.
Also the trend of micro-services is huge in which application logs are directly to proportional to the number of services, nodes and their maintenance. Every level introduced requires many levels of logs written to different places, to process all these TB's if not PB's of data and get value out of it search is mandatory.
Here's a sample of metrics from ILS at the time of writing this blog post:

and facebook states that it makes around 60+ million queries per day.
So to conclude the value implementing a search to the business is enormous and it provides better if not best user experience for your consumers, teams e.t.c..
That's it for now on why we need search I'll be discussing on some basic search concepts in my next post.
Happy Learning ✌
Comments
Post a Comment